はじめに
こんにちは!サイボウズ Developer Pioneer チームです。 今年もMaker Faire Tokyo 2023に出展しました!
展示物のうち1つ「アノ・イルカ」は、その昔様々なパソコンで知恵を貸してくれた伝説のイルカアシスタントを、この世に実態を持たせて蘇らせた作品です。ChatGPT と物理的な開発で、消せないアシスタントが爆誕しました。(※お前を消す方法) Maker Faire Tokyo 2023 のアシスタントをしてくれます。
アノ・イルカです🐬#MFTokyo2023 pic.twitter.com/UbrAkdDAcZ
— 出雲 沙斗美【いずも さとみ】 (@satomi_izumo) 2023年10月15日
「アノ・イルカ」の仕組みを2つの記事でご紹介します。
- OpenAI連携バックエンド編
- 画面・ハードウェア実装編
この記事は「OpenAI連携バックエンド編」です。
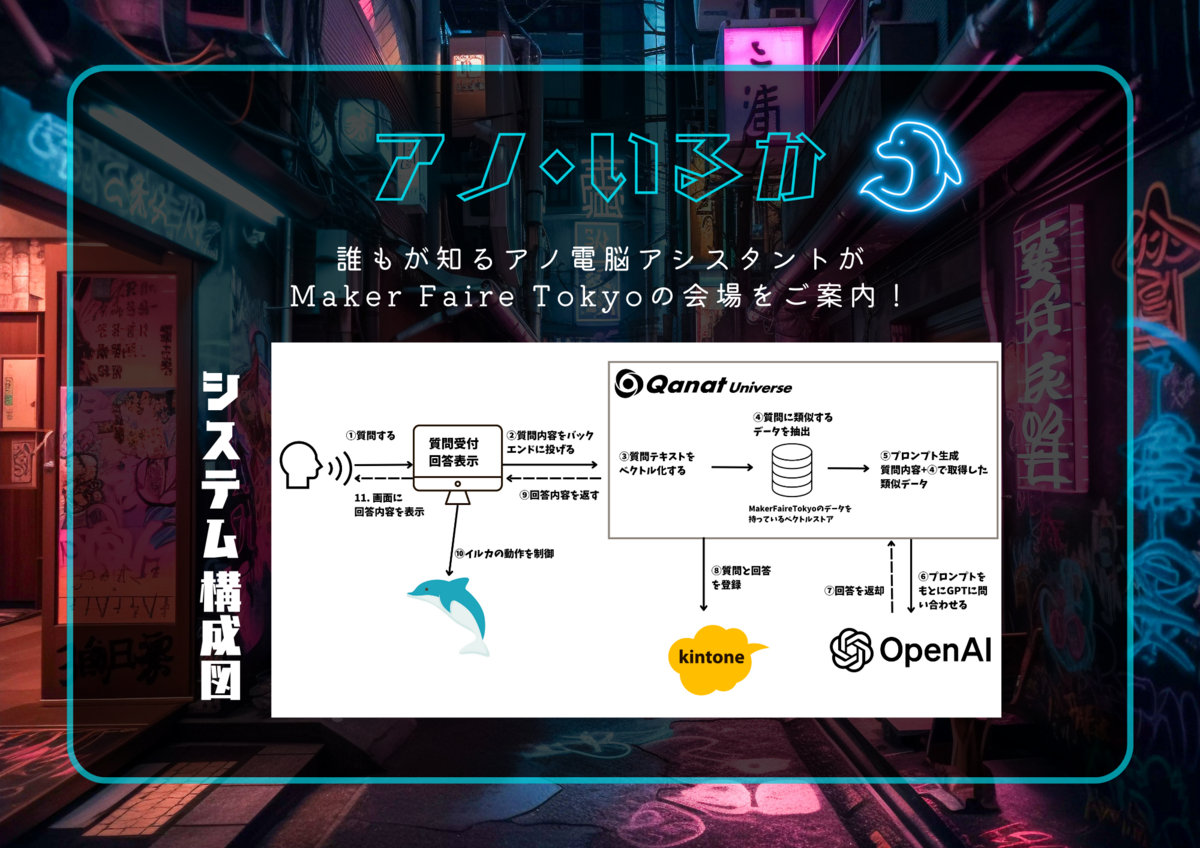
全体像
まずは、システムの全体像です。

この記事では、Qanat Universe 上で実装した内容(全体像の③〜⑨まで)をご紹介します。 Qanat Universe の代わりに、 Node-RED でも動作検証ができます。
用意するもの
- kintone環境
- kintoneアプリ・APIトークン
- Qanat Universe or Node-RED
- OpenAIアカウント
- APIキー
ChatGPTの注意ポイント
実装の前に、ChatGPTを使用する際に注意しないといけないポイントを確認しておきます。
制限
- gpt-3.5-turbo や gpt-4 は2021年9月までの情報
- 扱える文字列長(入出力合計)
- gpt-3.5-turbo の場合、日本語換算で2500字前後
- gpt-4 の場合、5000文字程度
つまり、何も考えずに gpt-3.5モデルを使用しても最新の情報を取得できませんし、プロンプト上で膨大な情報を渡すにも文字数制限に引っかかってしまいます。そのため、今回は事前に最新のデータ(引用して欲しいデータ)を保持するベクトルストアを用意し、そこから類似データを取得して、GPTにデータを渡し回答を生成してもらう仕組みで実装していきます。
🦜 LangChain を使う
今回の実装にはLangChainを使用します。 「もう知っている」という方は、このセクションを読み飛ばしてください。
LangChain とは
- Open AI、GPTなどの大規模言語モデルを使用したサービス開発に役立つLLMライブラリ
- Python / JavaScript 用のライブラリが公開されている(2023年8月時点)
LangChain でできること
Models
- LLM(大規模言語モデル)を使って、テキスト生成したい時に使う
Prompts
- LLMに渡すインプット部分を効率良くしたい時に使う
- 特定の振る舞いや条件設定を決めた文章を使用し、変数部分に{プレースホルダー}を使用して使いまわせる
Chains
- LLMChain
- ModelとPrompt Templateの汎用性を持たせたい時に使う
- Simple Sequential Chain
- 複数の動作(Modelの処理)をまとめたい時に使う
- RetrievalQAChain
- ベクトル検索が組み込まれてるチェーン
- 受け取ったクエリをEmbeddingでベクトル化する
- ベクトルストアと比較し、類似するベクトルを検索する
- ベクトルをキーにして、ベクトルストアに保存されている文章を取得する
- 取得した文章をプロンプトに入力し回答する
- ベクトル検索が組み込まれてるチェーン
- RetrievalQAChain
- 複数の動作(Modelの処理)をまとめたい時に使う
Agents
- タスク設計からAIに考えて実行して欲しい時に使う
- 道具(関数、関数の説明)とやりたいことを渡すと、使える道具からゴールまでのロジックを組み立ててくれる
Memory
- 過去のやり取り、文脈を維持しまま会話をしたい時に使う
- オンメモリに保存される
Indexes
- 必要な情報を与えたい、学習させたい時に使う
- gpt-3.5-turboやgpt-4は2021年9月までの知識で回答するため、最新のデータを含めて文章を生成して欲しい場合に活用する
- リソース: 必要なデータ・情報を用意する
- ベクター化: 文字列をベクトル情報に変換する
- 取得する(retrieve): レトリバー(回収する人)
- 参考リンク
LangChainを用いて、ベクトルストアの用意やGPTの細かい設定をしていきます。
シナリオ
今回は、QanatUniverse上でLangChainを使用して、以下の4つを実装します。
- APIのエンドポイントを作成する
- 質問テキストを受け取って、ベクトルストアから類似情報を抽出し、回答を生成する
- 回答をレスポンスで返す
- kintoneに質問・回答データを保存する
フローの全体像

こう見ると、めちゃくちゃシンプルです!
実装
では、シナリオの通り実装をしていきます。
1. APIのエンドポイントを作成する
http in ノードを使用します
| 設定項目 | 値 |
|---|---|
| メソッド | POST |
| URL | /XXX |
これで、https:~~~/XXXにPOSTリクエストができるようになりました。簡単ですね!
curl -X POST -d "text=ここにテキストを入れる" https://~~~~~/XXX
ちなみに、パラメータにtext="テキスト"のような形でリクエストをするとmsg.payload.text で値(この場合は"テキスト")を取り出すことができます!
つまりパラメータはmsg.payloadのオブジェクト内に格納されます。
2. 質問テキストを受け取って、ベクトルストアから類似情報を抽出し、回答を生成する
function ノードを使用します
設定タブ、初期化処理タブ、コードタブ部分を設定する

設定タブ
| モジュール名 | インポート名 |
|---|---|
| langchain/llms/openai | langchainLlmsOpenai |
| langchain/chains | langchainChains |
| langchain/embeddings/openai | langchainEmbeddingsOpenai |
| @notion/client | notionhqClient |
| langchain/document_loaders/web/notionapi | langchainDocumentLoadersWebNotionapi |
| faiss-node | faissNode |
| pickleparser | pickleparser |
| langchain/vectorstores/faiss | langchainVectorstoresFaiss |
※モジュール名を入れると自動でインポート名が生成されるため、そのまま使用するとよい
初期化処理タブ
OpenAI で使用したいモデルの定義や、ベクトルストアの初期化をここで定義していきます。
Vector Store の全体像
Vector Storeに保持したいデータを用意する〜Vector Storeにデータを保存するまでの一連の流れです。

▼参考:LangChainドキュメント Retrieval https://js.langchain.com/docs/modules/data_connection/
では、初期化処理タブを開いてコードを書いていきます。
// ノードをデプロイした時に一度だけ実行される const { OpenAI } = langchainLlmsOpenai; const { ConversationChain, RetrievalQAChain } = langchainChains; const { OpenAIEmbeddings } = langchainEmbeddingsOpenai; const { NotionAPILoader } = langchainDocumentLoadersWebNotionapi; const { FaissStore } = langchainVectorstoresFaiss; const OPNEAIAPIKEY = "sk-xxxxxxxxxxx"; const NOTION_INTEGRATION_TOKEN = "secret_xxxxxxxxx"; const NOTION_DATABASE_ID = "xxxxxxxxxxxxx"; const model = new OpenAI({ openAIApiKey: OPNEAIAPIKEY, temperature: 1.2, // ランダム性 max_tokens: 7000 }); try { // ================= // ① ドキュメントを用意 // Notion Loader // ================= const dbLoader = new NotionAPILoader({ clientOptions: { auth: NOTION_INTEGRATION_TOKEN, }, id: NOTION_DATABASE_ID, type: "database", onDocumentLoaded: (current, total, currentTitle) => { node.warn(`Loaded Page: ${currentTitle} (${current}/${total})`); }, callerOptions: { maxConcurrency: 64, // Default value }, }); // ================= // ② Document Load & Text Split // 取得したドキュメントをロードする // ================= const dbDocs = await dbLoader.load(); // ================= // ③ Embedding // ④ Vector Storeを作成 // ================= const vectorStore = await FaissStore.fromDocuments( dbDocs, new OpenAIEmbeddings({ openAIApiKey: OPNEAIAPIKEY, }) ); // ================= // ⑥ Vector Storeから類似データを抽出 // ベクトルストアをレトリーバーに変換して、取得したドキュメントを質問応答チェーンに適した形式で返させる // ================= const vectorStoreRetriever = vectorStore.asRetriever(); // fromLLメソッドを使用して、RetrievalQAChain(モデルとベクトルストア)を初期化 // 質問を受け取って意回答するQAチェーンを作成する const vs_chain = RetrievalQAChain.fromLLM( model, vectorStoreRetriever, ); // ================= // 初期化からコード側にvs_chain関数を渡す // ================= context.set("vs_chain", vs_chain); } catch (error) { if (error.response) { node.warn("error.response"); node.warn(error.response.status); node.warn(error.response.data); } else { node.warn("error.message"); node.warn(error.message); } }
解説
今回はNotionに持たせたデータをロードして、ベクトルストアに保存させていきます。 ベクトルストアには種類があり、2023年8月時点で20種類程度あります。 どのベクトルストアを使用するか判断に迷ったら、公式ドキュメントの 「Which one to pick?」 を確認すると良いかもしれません。
この記事では、Faiss を使用して実装しています。 (最初は、HNSWLib を予定していたのですが、使用したい本番環境にうまくインポートできなかったため変更しました)
最初のブロックでは、ライブラリ類のインポートと定数を定義しています。(APIキーは環境変数で定義するのが良いのだろうけど...)
また、使用するOpenAIのモデルを定義しておきます。templatureは0-2の値を設定でき、0にすると回答内容が変わらず、2に近づくほど回答のランダム性が増します。
次に、tryの中を説明していきます。まずは、事前に最新のドキュメント(引用して欲しいデータ)を用意します。CSVやPDFファイルでも問題ありませんが、今回はNotionに格納したデータをロードします。コード上の {id} や {auth} は、適宜変更が必要です。
本当はkintoneに格納されたデータをロードできたらよかったのですが...
Notion API | 🦜️🔗 Langchain
次にドキュメントをロードします。この辺は公式ドキュメント通りです。そして、ロードしたドキュメントをベクトル化しながらDBに保存していきます。{openAIApiKey} はOpnenAIのAPIを設定して下さい。vectorStore.asRetriever でベクトルストアを元に類似データを抽出させます。
最後に、RetrievalQAChainを使って複数の動作(Modelの処理)をまとめます。これはコードタブ部分で呼び出したいため、context.set("呼び出したい名前", 変数);を使って変数を渡しておきます。
コードタブ
次にコードタブにコードを書いていきます。
try { const vsChain = context.get("vs_chain"); const res = await vsChain.call({ query: `# 命令書 あなたは、イベントのアシスタントです。 以下の制約条件と入力文をもとに、日本語で回答を作成してください。 # 制約条件 ・350文字以内の日本語で回答すること ・学習データを元に、正確な情報を提供すること # 入力文: ・${msg.payload.text} # 出力文:` }); msg.question = msg.payload.text; msg.payload = res; return msg; } catch (error) { if (error.response) { node.warn("error.response"); node.warn(error.response.status); node.warn(error.response.data); } else { node.warn("error.message"); node.warn(error.message); } }
解説
まずは、初期化処理タブで渡したvs_chainをcontext.get使用して受け取っておきます。
次に、query部分でプロンプトを生成しGPTに渡します。
今回は、Maker Faireのアシスタントとして350文字程度の回答を生成してもらうための条件をつけました。
質問テキストは、${msg.payload.text}で取得しています。
最後に、質問と回答データを扱いやすいように、msg.question、msg.payloadに代入しておきます。
3. 回答をレスポンスで返す
http response ノードを使用します
| 設定項目 | 値 |
|---|---|
| ステータスコード | 200 |
| ヘッダ | Access-Control-Allow-Origin: * |
http inノードに紐づいたhttp responseノードは、自動でmsg.payloadをreturnします。
今回はmsg.payload = res;を返却しています。
4. kintoneに質問・回答データを保存する
質問内容と回答を保存する先にkintoneを使用します。
kintone
アプリを作成する
kintone環境にログインし、アプリを作成します。

| フィールド項目 | フィールド名 | フィールドコード |
|---|---|---|
| 文字列(一行) | 質問 | 質問 |
| 文字列(複数行) | 回答 | 回答 |
APIトークンを発行する
設定タブ>「APIトークン」を表示


APIトークンの値をコピーし、必ず「保存」と「アプリを更新」をしてください。
function ノードを使用
Qanat Universe または Node-REDの環境に戻り、functionノードを設定していきます。
コードタブ
kinotneにPOSTするためのパラメータを作成していきます。
msg.payload = { "app": XX, //kintoneのアプリ番号 "record": { "質問": { "value": msg.question }, "回答": { "value": msg.payload.text } } } return msg;
※kintoneのアプリ番号は、該当のkintoneアプリを表示した時のURLで確認できます。例:https://XXX.cybozu.com/k/100/ の場合、アプリ番号は100です。
http request ノードを使用
function ノードと http request ノードを繋ぐことで、function側で定義したパラメータをリクエストボディに含めてkintoneにPOSTします。 http request ノードでは、リクエスト先やリクエストヘッダ等を設定していきます。
| 設定項目 | 値 |
|---|---|
| メソッド | POST |
| URL | https://XXX.cybozu.com/k/v1/record.json |
| 出力形式 | JSON |
| ヘッダ | Content-Type: application/json X-Cybozu-API-Token: xxxxx(アプリで生成したAPIトークン) |
設定は以上です。
再掲となりますが、全体のフローはこのようになっています。
動作確認
- curlコマンドでAPIを叩いて回答が返ってきていること
- 例:
curl -X POST -d "text=ここに質問を入れる" https://~~~~~/XXX
- 例:
- kintoneに質問・回答データが溜まっていること
まとめ
流行りのLLM(今回はOpenAI)を使用した開発は、LangChainを使用することで、かなり手軽に実装できる印象を持ちました。特にデータローダー、ベクトルストアは、LangChainのおかげでサクッと実装できました。
「アノ・イルカ」のハードウェア実装部分や、画面実装の仕組みを知りたい方は、下記の記事もご確認ください。